
Linked Lists vs. Arrays
We've seen how these two data structures differ in both their implementations and runtime complexities.
struct ArrayNode
{
int prev_; // Previous "pointer"
int data_; // Data
int next_; // Next "pointer"
};
Our array would be an array of ArrayNodes instead of an array of integers
Of course, we'd want to have a class that implements this linked-list-array to have a full interface:
template <typename T>
class ArrayList
{
private:
struct ArrayNode
{
int prev_;
T data_;
int next_;
};
public:
ArrayList(unsigned MaxElements);
~ArrayList();
// Note: These 4 methods are all O(N)
const T& operator[](unsigned index) const;
T& operator[](unsigned index);
void insert(const T& value, unsigned index);
T remove_byindex(unsigned index);
void push_front(const T& value);
void push_back(const T& value);
void pop_front();
void pop_back();
void clear();
int find(const T& data) const;
bool empty() const;
unsigned size() const;
};
And in the constructor:private: int head_; int tail_; unsigned capacity_; ArrayNode *list_;
template <typename T>
ArrayList<T>::ArrayList(unsigned MaxElements)
{
head_ = NULL_NODE;
tail_ = NULL_NODE;
capacity_ = MaxElements;
list_ = new ArrayNode[capacity_];
}
A sample program run consisting of these statements: (The list shown is the logical ordering which is different from the physical order)const int NULL_NODE = -1; // 0 is a legal index, so -1 will be our NULL const int EMPTY_NODE = -2; // Set a node's prev/next to this to indicate it's available.
void TestArrayList()
{
ArrayList<char> foo(8); // Assume we don't know what an ArrayList is.
// Push back 5 characters, ABCDE
// A → B → C → D → E
for (char c = 'A'; c < 'F'; c++)
foo.push_back(c);
// Showing it as a linked list [or as an array]
foo.insert('X', 0); // X → A → B → C → D → E [XABCDE]
foo.remove_byindex(2); // X → A → C → D → E [XACDE]
foo.remove_byindex(3); // X → A → C → E [XACE]
foo.insert('Y', 2); // X → A → Y → C → E [XAYCE]
foo.push_front('P'); // P → X → A → Y → C → E [PXAYCE]
foo.push_front('Q'); // Q → P → X → A → Y → C → E [QPXAYCE]
foo.pop_back(); // Q → P → X → A → Y → C [QPXAYC]
foo.pop_front(); // P → X → A → Y → C [PXAYC]
foo[3] = 'J'; // P → X → A → J → C [PXAJC]
}
|
|
|
Details
A node could be laid out like this: (the actual ordering is not important)
The list after a constructor call:
ArrayList<char> list(8); (head=-1, tail=-1, -1 is the value of NULL_NODE)
Pushing 5 items:
The head "pointer" doesn't move during the five calls to push_back. However, the tail "pointer" moves with each call. (head=0, tail=0), then (head=0, tail=1), then (head=0, tail=2), etc.for (char c = 'A'; c < 'F'; c++) list.push_back(c);
When the loop ends, head is 0 and tail is 4:
| A |  |
| AB |  |
| ABC |  |
| ABCD |  |
| ABCDE |  |
list.insert('X', 0); (head=5, tail=4)
| XABCDE |  |
list.remove_byindex(2); (head=5, tail=4)
| XACDE |  |
list.remove_byindex(3); (head=5, tail=4)
| XACE |  |
list.insert('Y', 2); (head=5, tail=4)
| XAYCE |  |
list.push_front('P'); (head=3, tail=4)
| PXAYCE |  |
list.push_front('Q'); (head=6, tail=4)
| QPXAYCE |  |
list.pop_back(); (head=6, tail=2)
| QPXAYC |  |
list.pop_front(); (head=3, tail=2)
| PXAYC |  |
list[3] = 'J'; (head=3, tail=2)
| PXAJC |  |
With arrows to show the "links":
| PXAJC | 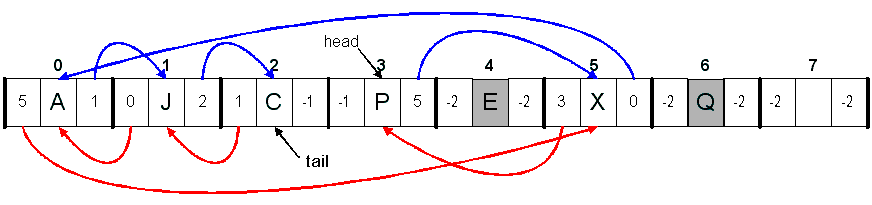 |
Finding empty blocks?
A freelist:
| PXAJC |  |